5. 正则表达式¶
我们常常需要判断一个给定字符串的合法性,比如一串数字是否是电话号码;一串字符是否是合法的 URL,Email 地址;用户输入的密码是否满足复杂度要求等等。
如果我们为每一种格式都定义一个判定函数,首先这种定义可能很复杂,比如电话号码可以为座机时表示为 010-12345678 ,也可以表示为 0510-12345678, 还可以是手机号 13800000000。这样代码的逻辑复杂度就线性增加。其次我们定义的函数功能很难重用,匹配 A 的不能匹配 B。能否有一个万能的函数,只要我们传入特定的参数就能实现我们特定的字符匹配需求呢?答案是肯定的。
在 字符串映射替换 中我们曾经使用过 re.sub 函数来替换多个字符串。这个问题看似简单,直接可以想到使用多次 replace 替换,但是会带来副作用,因为前一次被替换的字符串可能被再次替换掉,比如后面的替换字符串是前一个的子串,或者已经替换的字符串和前后字符正好形成了后来要替换的字符串。
一个可行的解决方案是使用第一个被替换字符串把字符串分割成多个子串,然后用第二个被替换字符串再次分割每一子串,依次类推,直至最后一个被替换字符分割完毕,再依次使用被替换字符进行合并逆操作。这种方案实现起来比较复杂,使用 re.sub 就简单多了。
正则表达式(Regular Expression)描述了一种字符串匹配的模式(Pattern),re 模块名就是正则表达式的缩写,它提供强大的字符匹配替换统计等操作,且适用于 Unicode 字符串。
5.1. 正则表达式¶
这里简要总结正则表达式的语法,不做深入扩展。
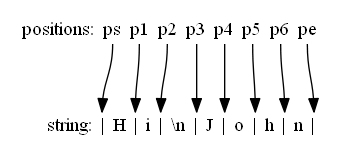
正则表达式中的两个概念:字符和位置
正则表达式中有两个概念,一个字符串包含若干个字符,每个字符在内存中都有对应的二进制编码,以及字符先后关系构成的位置,比如字符串开始位置和结束位置如图所示表示为 ps 和 pe。包含 N 个字符的字符串有 N+1 个位置,位置不占用内存,仅用于匹配定位。
正则表达式使用一些特殊字符(通常以 \ 开头)来表示特定的一类字符集(比如数字0-9)和字符位置(比如字符串开始位置)。它们被称为元字符(metacharacter)。元字符和其他控制字符构成的表达式被称为匹配模式(pattern)。
匹配过程中有一个位置指针,开始总是指向位置 ps,根据匹配模式每匹配一次,就将指针移动到匹配字符的后序位置,并尝试在每一个位置上进行模式匹配,直至尝试过 pe 位置后匹配过程结束。
\ 是转义字符,和其他语言中的转义字符作用类似,‘.’ 在正则表达式中表示匹配除换行符 \n 外的所有字符,如果要匹配 ‘.’ 自身,就要使用 ‘\ .’ 的形式。
由于 Python 字符串本身也采用 \ 作为转义符,所以正则表达式字符串前要加 r ,表示原始输入,以防转义冲突。
5.1.1. 匹配字符的元字符¶
| 元字符 | 字符集 | 非集 | 字符集 |
|---|---|---|---|
| . | 匹配除换行符 \n 外的所有字符 | \n | 换行符 \n |
| \d | 匹配数字 0-9 | \D | 非数字 |
| \s | 空白符: [<空格>trnfv] | \S | 非空白符 |
| \w | 匹配单词字符 | \W | 非单词字符 |
- d 是 digit numbers,s 是 sapce characters,w 是 word 的缩写。
- 元字符的非集也是元字符。
- 单词字符也即构成英文单词的字符,包括 [A-Za-z0-9_],对于中文来说,还包括 unicode 中的非特殊中文字符(比如中文标点符号)。
[…] 用于直接指定字符集,表示匹配其中任意一个:
- 可以直接给出,比如 [abc]
- 可以给定范围,比如 [a-c]
- 可以在开始位置添加 ^,表示取反,比如 [^a-c],表示 abc 以外的所有字符集。
- 如果要在 [] 中指定特殊字符,比如 ^,需要转义。
5.1.2. 匹配位置的元字符¶
| 元字符 | 字符集 | 非集 | 字符集 |
|---|---|---|---|
| ^ | 匹配字符串起始位置 ps | $ | 匹配字符串末尾位置 pe |
| \b | 匹配 \w 和 \W 之间位置,ps,p2,p3,pe | \B | \w 和 \W 之外位置,如图p1,p4,p5,p6 |
| \A | 等同 ^ | \Z | 等同 $ |
- ^ 和 $ 在多行模式下支持每行的起始和末尾位置匹配。\A 和 \Z 不支持多行模式。
- ^ 在数学中被称为 hat ,帽子总是戴在头上,匹配字符起始位置,而 $ 很像蛇的尾巴,匹配字符结尾。
- A 和 Z 分别是字母表的首尾字母,分别匹配字符起止位置。
- b 表示 between,是 \w 和 \W 单词字符和非单词字符之间的位置。
5.2. findall 和 finditer¶
findall(pattern, string, flags=0)
Return a list of all non-overlapping matches in the string.
findall() 方法返回匹配的所有子串,并把它们作为一个列表返回。匹配从左到右有序返回子串。如果无匹配,返回空列表。
使用 findall() 来验证上述元字符的功能是一个好方法。
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | import re
instr = "Hi\nJohn"
cpattern_list = [r'.', r'\n', r'\d', r'\D', r'\s', r'\S', r'\w', r'\W']
for i in cpattern_list:
print('\'Hi\\nJohn\' -> %02s ->' % i, re.findall(i, instr))
>>>
'Hi\nJohn' -> . -> ['H', 'i', 'J', 'o', 'h', 'n']
'Hi\nJohn' -> \n -> ['\n']
'Hi\nJohn' -> \d -> []
'Hi\nJohn' -> \D -> ['H', 'i', '\n', 'J', 'o', 'h', 'n']
'Hi\nJohn' -> \s -> ['\n']
'Hi\nJohn' -> \S -> ['H', 'i', 'J', 'o', 'h', 'n']
'Hi\nJohn' -> \w -> ['H', 'i', 'J', 'o', 'h', 'n']
'Hi\nJohn' -> \W -> ['\n']
|
字符集元字符返回的均是匹配的字符列表,而位置元字符返回的是位置,所以均是空字符,其中:
- ^ 和 $ 匹配位置 ps 和 pe。
- \b 匹配到位置 ps,p2,p3 和 pe。
- \B 匹配到位置 p1,p4,p5 和 p6。
0 1 2 3 4 5 6 7 8 9 10 11 | instr = "Hi\nJohn"
ppattern_list = [r'^', r'$', r'\A', r'\Z', r'\b', r'\B']
for i in ppattern_list:
print('\'Hi\\nJohn\' -> %02s ->' % i, re.findall(i, instr))
>>>
'Hi\nJohn' -> ^ -> ['']
'Hi\nJohn' -> $ -> ['']
'Hi\nJohn' -> \A -> ['']
'Hi\nJohn' -> \Z -> ['']
'Hi\nJohn' -> \b -> ['', '', '', '']
'Hi\nJohn' -> \B -> ['', '', '', '']
|
为了展示 \b 和 \B 确实匹配了相应位置,我们尝试匹配这个位置的下一个字符,由于 . 不能匹配 \n ,所以要指定选择分支 (.|n)。
0 1 2 3 4 5 6 | instr = "Hi\nJohn"
print(re.findall(r'\b(.|\n)', instr))
print(re.findall(r'\B.', instr))
>>>
['H', '\n', 'J']
['i', 'o', 'h', 'n']
|
finditer(pattern, string, flags=0)
Return an iterator over all non-overlapping matches in the
string. For each match, the iterator returns a match object.
finditer() 方法与 findall() 唯一不同在于返回的不是列表,而是一个返回 match 对象的迭代器,无匹配,则返回内容为空迭代器。
0 1 2 3 4 5 6 7 8 9 10 | instr = "test1 test2"
print(re.findall(r'(?<=test).', instr))
it = re.finditer(r'(?<=test).', instr)
print(type(it))
for i in it:
print(i.group(), end=' ')
>>>
['1', '2']
<class 'callable_iterator'>
1 2
|
5.3. 重复字符¶
有了元字符,只能够匹配特定的单个字符或者位置,有了重复字符的参与,就可以生成更加复杂的模式,比如我们要匹配 8 个数字,不用写 8个 \d,而直接用 \d{8}。
重复字符又称为数量符,常用的重复字符表如下:
| 数量符 | 描述 |
|---|---|
| * | 重复 >=0 次 |
| + | 重复 >=1 次 |
| ? | 重复 0 或 1 次 |
| {m} | 重复 m 次 |
| {m,n} | 重复 m 到 n 次 |
| (,n) | 重复 0 到 n 次 |
| (m,) | 重复 m 到无限次 |
- 重复字符用在匹配字符的元字符之后,也可以用在分组后,参考 或逻辑和分组 。不可单独使用,功能作用在前一个元字符或者分组上。
- 以上重复模式默认为贪婪模式,总是选择尽量多匹配的分支,比如 {m, n} 就尽量选择靠近 n 的分支,可以在其后加 ‘?’ 变成非贪婪模式,比如 *?,{m,n}?。
继续借助 findall() 方法来验证以上重复字符的功能:
0 1 2 3 4 5 6 7 8 9 10 11 12 | instr = "HHH"
pattern_list = [r'H*', r'H+', r'H?', r'H{2}', r'H{2,3}', r'H{2,}', r'H{,3}']
for i in pattern_list:
print('\'HHH\' -> %06s' % i, re.findall(i, instr))
>>>
'HHH' -> H* ['HHH', '']
'HHH' -> H+ ['HHH']
'HHH' -> H? ['H', 'H', 'H', '']
'HHH' -> H{2} ['HH']
'HHH' -> H{2,3} ['HHH']
'HHH' -> H{2,} ['HHH']
'HHH' -> H{,3} ['HHH', '']
|
这里以 ‘H*’ 简述匹配过程:
- 指针 p 指向 ps,尝试尽量多的匹配, 匹配到 ‘HHH’,p 指向 pe。
- 指针指向 pe 匹配到 0 次,也即 ‘’。
所以以上结果中含有 ‘’ 的情况均是因为在 pe 处匹配 0 次出现的。
5.3.1. 非贪婪模式¶
0 1 2 3 4 5 6 7 8 9 10 11 12 | instr = "HHH"
pattern_list = [r'H*', r'H+', r'H?', r'H{2}', r'H{2,3}', r'H{2,}', r'H{,3}']
for i in pattern_list:
print('\'HHH\' -> %07s' % (i + r'?'), re.findall(i + r'?', instr))
>>>
'HHH' -> H*? ['', '', '', '']
'HHH' -> H+? ['H', 'H', 'H']
'HHH' -> H?? ['', '', '', '']
'HHH' -> H{2}? ['HH']
'HHH' -> H{2,3}? ['HH']
'HHH' -> H{2,}? ['HH']
'HHH' -> H{,3}? ['', '', '', '']
|
这里以 ‘H*’ 简述非贪婪模式匹配过程:
- 指针 p 指向 ps,尝试尽量少的 0 次匹配, 匹配到 ‘’,p 指向 p1。
- 依次采用尽量少的 0 次匹配,直至指向 pe 再次匹配到 ‘’。
所以 ‘H*’ 最后匹配的 ‘’ 个数是 H 的个数 3 加 1。
5.4. 或逻辑和分组¶
前文提到电话号码可以有不同的表示形式,比如区号分 3 位和 4 位,手机号总是 13 位。这就用到了或逻辑运算符 |。
- 它用在多个表达式式中间,表示匹配其中任何一个,比如 A | B | C,它总是先尝试匹配左边的表达式,一旦成功匹配则跳过右边的表达式。
- 如果 | 没有包含在 () 中,则它的范围是整个表达式。
0 1 2 3 4 | instr = "color colour"
print(re.findall(r'color|colour', instr))
>>>
['color', 'colour']
|
使用 () 括起来的表达式,被称为分组(Group)。重复字符可以加在分组之后。
0 1 2 3 4 | instr = "color colour"
print(re.findall(r'(colo)?', instr))
>>>
['colo', '', '', 'colo', '', '', '']
|
表达式中的每个分组从左至右被自动从 1 编号,可以在表达式中引用编号。也可以为分组指定名字。
| 分组操作 | 描述 |
|---|---|
| (exp) | 匹配exp,并自动编号 |
| <id> | 引用编号为<id>的分组匹配到的字符串,例如 (d)abc1 |
| (?P<name>exp) | 为分组命名,例如 (?P<id>ab){2},匹配 abab |
| (?P=name) | 引用命名为<name>的分组匹配到的字符串,例如 (?P<name>d)abc(?P=name) |
| (?:exp) | 匹配exp,但跳过匹配字符,且不为该分组编号 |
| (?#comment) | 正则表达式注释,不影响正则表达式的处理 |
0 1 2 3 4 5 6 7 8 | instr = "1abc1 2abc2"
print(re.findall(r'(\d)abc\1', instr))
instr = "1abc1 2abc2"
print(re.findall(r'(?P<name>\d)abc(?P=name)', instr))
>>>
['1', '2']
['1', '2']
|
分组操作还支持以下语法,用于匹配特定位置:
| 分组位置操作 | 描述 |
|---|---|
| (?=exp) | 匹配exp字符串前的位置 |
| (?<=exp) | 匹配exp字符串后的位置 |
| (?!exp) | 不匹配exp字符串前的位置 |
| (?<!exp) | 不匹配exp字符串后的位置 |
0 1 2 3 4 5 6 7 8 9 10 | instr = "0abc1"
print(re.findall(r'(?=abc).', instr))
print(re.findall(r'(?<=abc).', instr))
print(re.findall(r'(?!abc).', instr))
print(re.findall(r'(?<!abc).', instr))
>>>
['a']
['1']
['0', 'b', 'c', '1']
['0', 'a', 'b', 'c']
|
位置匹配可以对匹配字符进行条件选择,例如匹配三个连续的数字,且其后不能再跟数字:
0 1 2 3 4 | instr = "111a1222"
print(re.findall(r'\d{3}(?!\d)', instr))
>>>
['111', '222']
|
5.5. 匹配模式选项¶
re 模块定义了 6 种模式选项:
- re.I (re.IGNORECASE): 匹配时忽略大小写。
- re.M (re.MULTILINE): 多行模式,改变’^’和’$’的行为,可以匹配任意一行的行首和行尾。
- re.S (re.DOTALL): 点任意匹配模式,此时’.’ 匹配任意字符,包含 \n。
- re.L (re.LOCALE): 使预定字符类 w W b B s S 取决于当前区域设定。
- re.U (re.UNICODE): 使预定字符类 w W b B s S d D 取决于 unicode 定义的字符属性。
- re.X (re.VERBOSE): 详细模式。此模式下正则表达式可以写成多行,忽略空白字符,并可以加入注释。
以下两个表达式是等价的:
0 1 2 | instr = "Hi\nJohn"
print(re.findall(r'\b(.|\n)', instr))
print(re.findall(r'\b(.)', instr, re.S))
|
以下两个正则表达式也是等价的:
0 1 2 3 | pattern = re.compile(r'''\d + # the integral part
\. # the decimal point
\d * # some fractional digits''', re.X)
pattern = re.compile(r"\d+\.\d*")
|
5.6. compile¶
compile(pattern, flags=0)
Compile a regular expression pattern, returning a pattern object.
compile() 方法将字符串形式的表达式编译成匹配模式对象。 第二个参数 flag 指定匹配模式类型,可以按位或运算符 ‘|’ 生效多种模式类型,比如re.I | re.M。另外,也可以在表达式字符串中指定模式,以下两个表达式是等价的:
0 1 | re.compile(r'abc', re.I | re.M)
re.compile('(?im)abc')
|
将表达式编译成匹配模式对象后,可以重复使用该对象,无需每次都传入表达式。
0 1 2 3 4 5 6 | pattern = re.compile(r'(?i)hi')
print(pattern.findall("Hi\nJohn"))
print(pattern.findall("hi\nJohn"))
>>>
['Hi']
['hi']
|
pattern 对象提供了几个可读属性用于查看表达式的相关信息:
- pattern: 匹配模式对应的表达式字符串。
- flags: 编译时用的匹配模式选项,数字形式。
- groups: 表达式中分组的数量。
- groupindex: 表达式中有别名的分组的别名为键、以组编号为值的字典,不含无别名的分组。
0 1 2 3 4 5 6 7 8 9 10 11 12 13 | def print_pattern_obj(p):
print("p.pattern\t:", p.pattern)
print("p.flags\t\t:", p.flags)
print("p.groups\t:", p.groups)
print("p.groupindex\t:", p.groupindex)
p = re.compile(r'(key\d{1} *)(: *val\d{1})(?P<comma> *,)', re.I)
print_pattern_obj(p)
>>>
p.pattern : (key\d{1} *)(: *val\d{1})(?P<comma> *,)
p.flags : 34
p.groups : 3
p.groupindex : {'comma': 3}
|
5.7. match 和 search¶
match(pattern, string, flags=0)
Try to apply the pattern at the start of the string, returning
a match object, or None if no match was found.
match() 方法从字符段头部开始判断是否匹配,一旦匹配成功,返回一个 Match 对象,否则返回 None。Match 对象保存了首次匹配的结果。
match() 方法与字符串方法 startswith() 很像,只是它使用正则表达式来判断字符头部是否满足条件。
0 1 2 3 4 | m = re.match(r'\d{3}', 'a123')
print(m)
>>>
None
|
由于字符串 ‘a123’ 不是以 3 个数字开头的字符串,所以返回 None。再看一个更复杂的例子:
0 1 2 3 4 5 | pattern = re.compile(r'(key\d{1} *)(: *val\d{1})(?P<comma> *,)')
m = pattern.match('key0 : val0, key1 : val1')
print(type(m))
>>>
<class '_sre.SRE_Match'>
|
search(pattern, string, flags=0)
Scan through string looking for a match to the pattern, returning
a match object, or None if no match was found.
search() 搜索整个字符串,查找匹配的字符,找到后返回一个 match 对象,否则返回 None。
0 1 2 3 4 5 | pattern = re.compile(r'(key\d{1} *)(: *val\d{1})(?P<comma> *,)')
m = pattern.search('key: val, key0 : val0, key1 : val1')
print(m)
>>>
<_sre.SRE_Match object; span=(10, 22), match='key0 : val0,'>
|
示例尝试匹配 key 和 val 后有一数字的键值对,如果使用 match() 则会返回 None。
5.7.1. match 对象¶
match 对象保存一次匹配成功的信息,有很多方法会返回该对象,这里对它包含的属性进行介绍。使用上例中的匹配对象,将属性打印如下:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | def print_match_obj(m):
print("m.re\t\t:", m.re)
print("m.string\t:", m.string)
print("m.pos\t\t:", m.pos)
print("m.endpos\t:", m.endpos)
print("m.lastindex\t:", m.lastindex)
print("m.lastgroup\t:", m.lastgroup)
print("m.group(1,2)\t:", m.group(1, 2))
print("m.groups()\t:", m.groups())
print("m.groupdict()\t:", m.groupdict())
print("m.start(2)\t\t:", m.start(2))
print("m.end(2)\t\t:", m.end(2))
print("m.span(2)\t\t:", m.span(2))
print("m.expand(r'\\1-\\2\\3')\t\t:", m.expand(r'\1-\2\3'))
print("m.expand(r'\\1-\\2g<3>')\t\t:", m.expand(r'\1-\2\g<3>'))
print("m.expand(r'\\1-\\2g<comma>')\t:", m.expand(r'\1-\2\g<comma>'))
print_match_obj(m)
>>>
m.re : re.compile('(key\\d{1} *)(: *val\\d{1})(?P<comma> *,)')
m.string : key0 : val0, key1 : val1
m.pos : 0
m.endpos : 24
m.lastindex : 3
m.lastgroup : comma
m.group(1,2) : ('key0 ', ': val0')
m.groups() : ('key0 ', ': val0', ',')
m.groupdict() : {'comma': ','}
m.start(2) : 5
m.end(2) : 11
m.span(2) : (5, 11)
m.expand(r'\1-\2g<comma>') : key0 -: val0,
|
- re:匹配时使用的模式
- string:要进行匹配操作的字符串
- pos 和 endpos:分别表示开始和结束搜索的位置索引,pos 等于 ps,也即 0 位置;这里的 endpos 为 24,等于 ps,是字符 val1 后的位置,也即 string 的长度。
- lastindex:最后一个匹配的分组编号,我们的模式中有 3 个分组,第 3 个分组用于匹配一个 ‘,’。
- lastgroup:最后一个匹配的分组的别名,如果没有别名,则为 None。
- group():group() 方法使用编号后者别名获取分组,参考 match.group 。
- groups():groups() 方法等价于 group(1,2,…last),返回所有分组匹配的子串,是一个元组。
- groupdict():groupdict() 方法返回分组中有别名的分组子串,是一个字典,例如 {‘comma’: ‘,’}。
- start() 和 end() :分别返回指定分组匹配的字符串的起止字符在 string 上的位置索引值,支持编号和别名。
- span(group):等价于 (start(group), end(group)),返回元组类型。
- expand(template):将匹配到的分组代入 template 中然后返回,参考 match.expand 。
5.7.2. match.group¶
group() 方法获取一个或多个分组匹配的字符串:
- 不提供参数,等同于 group(0),编号 0 代表返回整个匹配的子串。
- 指定多个编号参数时将返回一个元组。
- 可以使用编号也可以使用别名;
- 没有匹配字符串的分组返回 None,匹配了多次的组返回最后一次匹配的子串。
0 1 2 3 4 5 6 7 8 9 10 | pattern = re.compile(r'(key\d{1} *)(: *val\d{1})(?P<comma> *,)')
m = pattern.match('key0 : val0, key1 : val1')
print(m.group())
print(m.group(1, 2))
print(m.group(1, 2, 'comma'))
>>>
key0 : val0,
('key0 ', ': val0')
('key0 ', ': val0', ',')
|
5.7.3. match.expand¶
expand(template) 方法将匹配到的分组代入 template 中然后返回。template 中支持两种方式引用分组:
- 可以使用 id 或 g<id> 引用分组编号,例如 1 和 g<1> 是等价的,编号从 1 开始。
- g<name> 通过别名引用分组,例如 g<comma>。
以下三种方式是等价的。
0 1 2 3 4 5 6 7 8 9 10 | pattern = re.compile(r'(key\d{1} *)(: *val\d{1})(?P<comma> *,)')
m = pattern.match('key0 : val0, key1 : val1')
print("m.expand(r'\\1-\\2\\3')\t\t:", m.expand(r'\1-\2\3'))
print("m.expand(r'\\1-\\2g<3>')\t\t:", m.expand(r'\1-\2\g<3>'))
print("m.expand(r'\\1-\\2g<comma>')\t:", m.expand(r'\1-\2\g<comma>'))
>>>
m.expand(r'\1-\2\3') : key0 -: val0,
m.expand(r'\1-\2g<3>') : key0 -: val0,
m.expand(r'\1-\2g<comma>') : key0 -: val0,
|
5.8. split¶
split(pattern, string, maxsplit=0, flags=0)
Split the source string by the occurrences of the pattern,
returning a list containing the resulting substrings.
split() 方法按照匹配的子串将 string 分割后返回列表。maxsplit 用于指定最大分割次数,不指定将全部分割。
0 1 2 3 4 | p = re.compile(r'[, \-\*]')
print(p.split('1,2 3-4*5'))
>>>
['1', '2', '3', '4', '5']
|
5.9. sub 和 subn¶
sub(pattern, repl, string, count=0, flags=0)
Return the string obtained by replacing the leftmost
non-overlapping occurrences of the pattern in string by the
replacement repl.
sub() 方法使用 repl 替换 string 中每一个匹配的子串后返回替换后的字符串。repl 接受两种类型的参数:
- 当 repl 是一个字符串时,可以使用 id 或 g<id>,g<name> 引用分组,id 编号从 1 开始。
- 当 repl 是一个函数时,它只接受一个match对象作为参数,并返回一个用于替换的字符串(返回的字符串中不可再引用分组)。
count用于指定最多替换次数,不指定时全部替换。
0 1 2 3 4 5 6 7 8 9 10 11 | p = re.compile(r'(\S+) (\S+)')
instr = '1970-01-01 00:00:00'
print(p.sub(r'\2 \1', instr))
def func(m):
return ' '.join([m.group(2), m.group(1)])
print(p.sub(func, instr))
>>>
00:00:00 1970-01-01
00:00:00 1970-01-01
|
示例用于互换年月日和时分秒位置。
subn(pattern, repl, string, count=0, flags=0)
Return a 2-tuple containing (new_string, number).
subn() 方法参数与 sub() 一致,但是它返回一个元组,元组的格式为 (sub(…), 替换次数)。 例如:
0 1 2 3 4 5 6 7 8 9 10 11 | p = re.compile(r'(\S+) (\S+)')
instr = '1970-01-01 00:00:00'
print(p.subn(r'\2 \1', instr))
def func(m):
return ' '.join([m.group(2), m.group(1)])
print(p.subn(func, instr))
>>>
('00:00:00 1970-01-01', 1)
('00:00:00 1970-01-01', 1)
|
5.10. escape¶
escape(pattern)
Escape all the characters in pattern except ASCII letters, numbers and '_'.
escape() 方法对表达式中所有可能被解释为正则运算符的字符进行转义。如果字符串很长且包含很多特殊技字符,而又不想输入一大堆反斜杠,或者字符串来自于用户,且要用作正则表达式的一部分的时候,需要使用这个函数。
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | instr = "* and ?."
map_dict = {'?' : '*', '*' : '?'}
def replace_strs(instr, map_dict, count=0):
import re
re_dict = dict((re.escape(i), j) for i, j in map_dict.items())
print(re_dict)
pattern = re.compile('|'.join(re_dict.keys()))
return pattern.sub(lambda x: re_dict[re.escape(x.group(0))], instr, count)
print(replace_strs(instr, map_dict))
>>>
{'\\?': '*', '\\*': '?'}
? and *.
|
如果我们在编译 pattern 时,直接提供表达式字符串参数,可以在字符串前加 r,如果表达式存储在其他格式的变量中,就需要 escape() 处理。